Server administration
Configuration repository
The configuration defined on the server is stored in a local git repository, in /var/rudder/configuration-repository.
This repository contains the history of the configuration, and in some cases may also manage
the shared files in /var/rudder/configuration-repository/shared-files.
| The files in this repository (outside of shared-files) should generally not be edited outside of Rudder as they contains generated IDs and there is a risk of corrupting the configuration data. |
You can synchronize this repository, for example if you want to synchronize configurations between a test and a prod environment. It allows having exactly the same configuration (group definition, techniques, directives, rules) with a different set of nodes.
In this case synchronized servers need to have exactly the same Rudder version.
Archives
Archive use cases
The archive feature of Rudder allows to:
-
Exchange configuration between multiple Rudder instances, in particular when having distinct environments;
-
Keep an history of major changes.
Changes testing
Export the current configuration of Rudder before you begin to make any change you have to test: if anything goes wrong, you can return to this archived state.
Changes qualification
Assuming you have multiple Rudder instances, each on dedicated for the development, qualification and production environment. You can prepare the changes on the development instance, export an archive, deploy this archive on the qualification environment, then on the production environment.
|
Versions of the Rudder servers
If you want to export and import configurations between environments, the version of the source and target Rudder server must be exactly the same. If the versions don’t match (even if only the minor versions are different), there is a risk that the import will break the configuration on the target Rudder server. |
Concepts
In the Utilities → Archives page of the Rudder Server web interface, you can export and import the configuration of Rudder Groups, Directives and Rules. You can either archive the complete configuration, or only the subset dedicated to Groups, Directives or Rules.
When archiving configuration, a 'git tag' is created into /var/rudder/configuration-repository.
This tag is then referenced in the Rudder web interface, and available for download
as a zip file. Please note that each change in the Rudder web interface is also
committed in the repository.
|
Currently, Archiving also add all unstaged files in the commit in /var/rudder/configuration-repository. So it can change the Techniques used by Rudder (Rudder uses the latest commit in git as a reference). You should away ensure that there are no unstaged files before doing any Archive to avoid any side effect. In the future, Rudder will prevent any Archive in Techniques or Generic Methods are not committed. |
The content of this repository can be imported into any Rudder server (with the same version).
Archiving
To archive Rudder Rules, Groups, Directives, or make a global archive, you need to go to the Utilities → Archives page of the Rudder Server web interface.
To perform a global archive, the steps are:
-
Click on Archive everything - it will update the drop down list Choose an archive with the latest data
-
In the drop down list Choose an archive, select the newly created archive (archives are sorted by date), for example 2015-01-08 16:39
-
Click on Download as zip to download an archive that will contains all elements.
Importing configuration
On the target server, importing the configuration will "merge" them with the existing configuration: every groups, rules, directives or techniques with the same identifier will be replaced by the import, and all others will remain untouched.
To import the archive on the target Rudder server, you can follow the following steps:
-
Uncompress the zip archive in
/var/rudder/configuration-repository -
If necessary, correct all files permissions:
chown -R root:rudder directives groups parameters ruleCategories rules techniques -
Add all files in the git repository:
git add . && git commit -am "Importing configuration" -
In the Web interface, go to the Settings > General page, at the bottom of the page in Manage Technique library section, click Reload Techniques button
-
Finally, in the Web interface, go to the Utilities > Archives page, in the Global Archive section (first section), select Latest Git commit in the drop down list, and click on Restore everything to restore the configuration.
|
You can also perform the synchronization from on environment to another by using git, through a unique git repository referenced on both environment. For instance, using one unique git repository you can follow this workflow:
=== Deploy a preconfigured instance You can use the procedures of Archiving and Restoring configuration to deploy preconfigured instance. You would prepare first in your labs the configuration for Groups, Directives and Rules, create an Archive, and import the Archive on the new Rudder server installation == Event Logs Every action happening in the Rudder web interface are logged in the PostgreSQL database. The last 1000 event log entries are displayed in the Utilities → Event Logs page of Rudder web application. Each log item is described by its 'ID', 'Date', 'Actor', and 'Event' 'Type', 'Category' and 'Description'. For the most complex events, like changes in nodes, groups, techniques, directives, deployments, more details can be displayed by clicking on the event log line.
== Health Check
To ensure the health of Rudder, some checks are executed every 6 hours by default. To change the period
you can add
A notification will be displayed if at least one Warning or Critical has been returned by latest Health Check run. 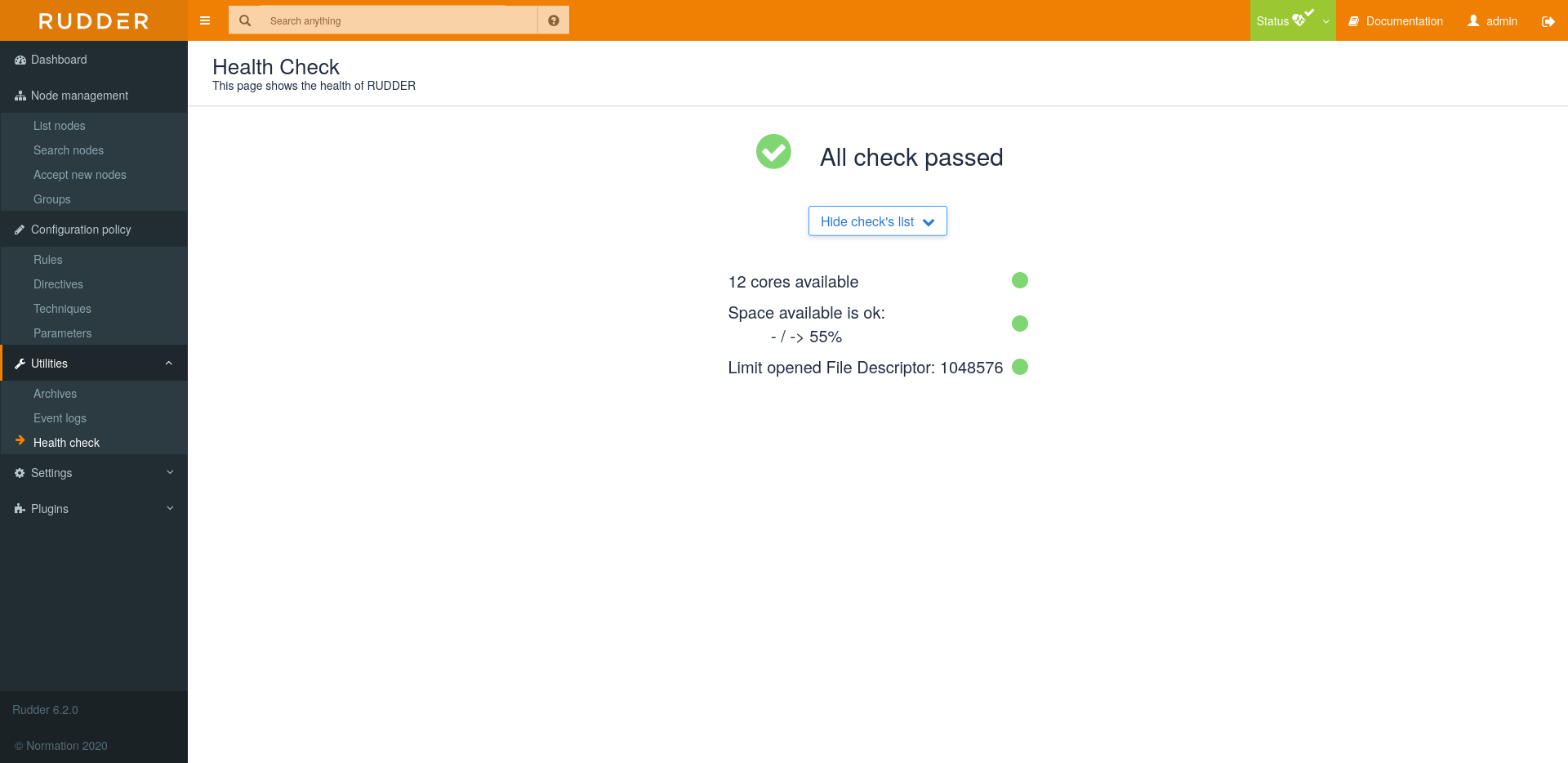
== Policy Server The Settings → General page sum-up information about Rudder policy server and its parameters. === Configure allowed networks Here you can configure the networks from which nodes are allowed to connect to Rudder policy server to get their updated rules. You can add as many networks as you want, the expected format is:
=== Clear caches Clear cached data, like node configuration. That will trigger a full redeployment, with regeneration of all policies files. === Reload dynamic groups Reload dynamic groups, so that new nodes and their inventories are taken into account. Normally, dynamic group are automatically reloaded unless that feature is explicitly disable in Rudder configuration file. == Basic administration of Rudder services === Restart the agent of the node To restart the Rudder Agent, use following command on a node: rudder agent restart |
This command can take more than one minute to restart the agent daemons. This is not a bug, but an internal protection system of the agent.
=== Restart the root rudder service
==== Restart everything
You can restart all components of the Rudder Root Server at once:
systemctl restart rudder-server
==== Restart only one server component
Here is the list of the components of the root server with a brief description of their role, and the command to restart them:
- Policy server
-
Distribute the configuration to the nodes.
systemctl restart rudder-agent # or, depending on the platform service rudder-agent restart
- Web server application
-
Execute the web interface and the server that handles the new inventories.
systemctl restart rudder-jetty
- Web server front-end
-
Handle the connection to the Web interface, the received inventories and the sharing of the UUID Rudder Root Server.
systemctl restart apache2 # or, depending on the platform systemctl restart httpd
- LDAP server
-
Store the inventories and the Node configurations.
systemctl restart rudder-slapd
- SQL server
-
Store the received reports from the nodes.
# The name of the service may vary if you installed # non-standard postgresql packages # You can list them with systelctl --list-units --all | grep postgresql systemctl restart postgresql
== Communication resilience in case of network or Rudder server outage
=== Between nodes and their policy server
When the connection between a policy server and one of its managed nodes breaks:
-
All current policies continue to be applied by the nodes at defined execution interval
-
Agent continues to generate local logs
=== Between root and relay
When the connection between the root server and a relay breaks:
-
All current policies continue to be served by the relays
-
File sharing between nodes under the relay stays possible
It is however not possible to:
-
Accept a new node
-
Continue to process inventories and reports
| Processing old inventories and reports is supported on relay side and will be supported by the root server in a future version, which will allow proper data back-filling after network or server outage. |
== rudder-cf-serverd logging
The log level of the policy server daemon is configurable. By default it logs all connections from nodes, to allow proper auditing of node connections, but you can disable these logs (or increase the log level). To only log errors:
-
On systemd systems
-
Create a
/etc/systemd/system/rudder-cf-serverd.service.d/override.conffile containing:
-
[Service] Environment=VERBOSITY_OPTION=
-
Run
systemctl daemon-reloadthensystemctl restart rudder-cf-serverd-
On systems using the init script
-
-
Edit the
/etc/default/rudder-agentfile:
# You need to uncomment and let empty CFENGINE_COMMUNITY_PARAMS_1=""
-
Restart the service with
service rudder-agent restart
Verbosity options can be:
-
empty for only errors
-
--informfor basic messages -
--verbosefor very detailed logs -
--debugfor unreasonnably detailed logs
== Optional usage survey and data collection
If you give it the right to do so, Rudder will collect anonymous data about your rudder instance sizing. This information are mainly used to help us understand what kind of sizing performance should be check for, and what versions of OS and languages we need to support.
In any case, that data collection is anonymous and optional. And to be very clear: we know what prod is, so we won’t ever send configuration related data out of Rudder server. Configuration is for the nodes and relays only.
=== Configuration of survey level
The configuration is available in the settings pages, under the name Usage Survey.
There is three level of data collection: - full metrics (see below for what is collected) - minimal, - nothing, zero, nada.
To change you usage level, just select the new one and save.
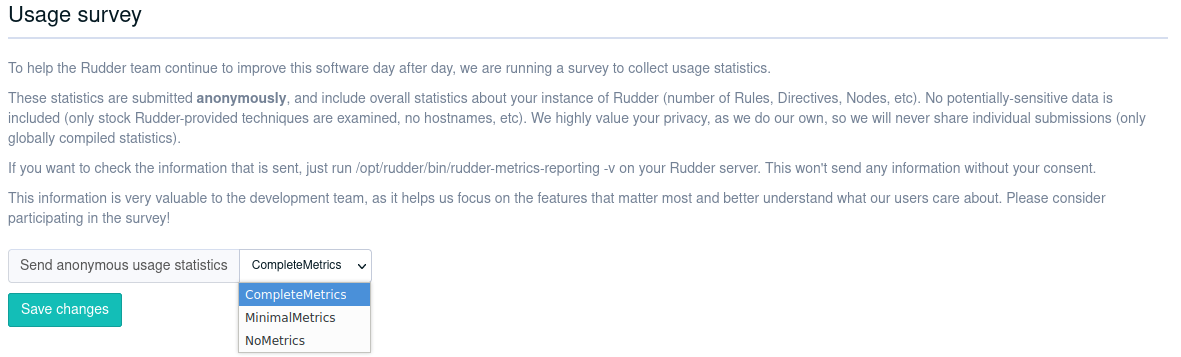
=== Metric collected
The maximum level of data collected get information:
-
Rudder server installation date and version
-
list of installed plugins
-
number of nodes
-
DB size
-
setting for audit log, workflow, policy mode, report mode
-
OS name and version
-
sizing of compliance report in DB: archive TTL, DB size,
=== Technical details
The logic of what is sent is handled by the script /opt/rudder/bin/rudder-metrics-reporting.
You can go by yourself and see what is sent, how, or just replace it by a noop script if you wish.
← REST API Agent administration →