Rudder architecture
Inventory workflow, from nodes to Root server
One of the main information workflow in a Rudder managed system is the node’s inventory one.
Node inventories are generated on nodes, are sent to the node policy server (be it a Relay or the Root server) up to the Root server, and stored in the Rudder database (technically an LDAP server), waiting for later use.
The goal of that section is to detail the different steps and explain how to spot and solve a problem on the inventory workflow. Following diagram sum up the whole process.
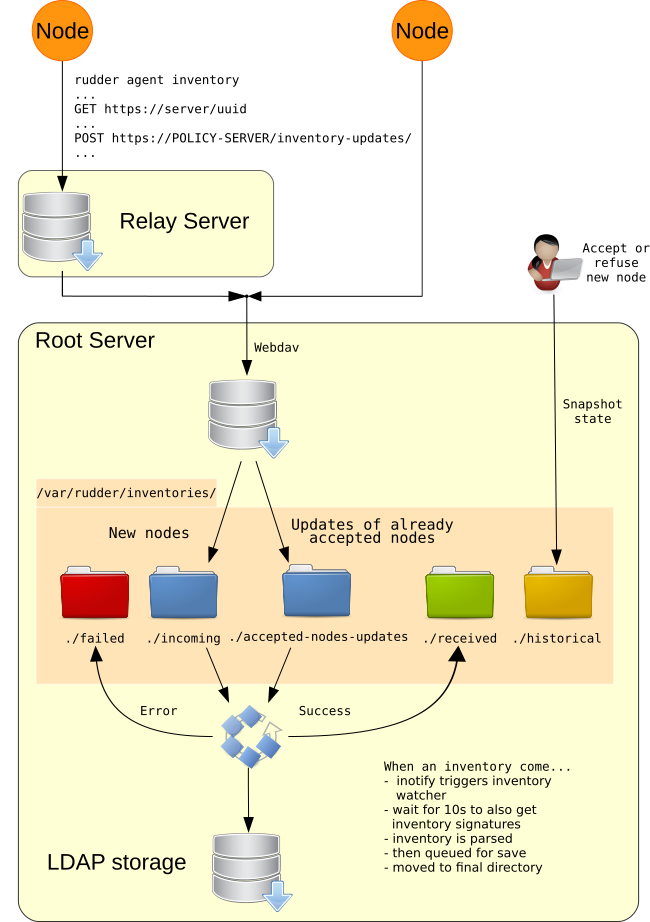
Processing inventories on node
Inventories are generated daily during an agent run in the 00:00-06:00 time frame window local to the node. The exact time is randomly spread on the time frame for a set of nodes, but each node will always keep the same time (modulo the exact time of the run).
User can request the generation and upload of inventory with the command:
rudder agent inventory
In details, generating inventory does:
-
ask the node policy server for its UUID with an HTTP GET on
https://server/uuid, -
generate an inventory by scanning the node hardware and software components,
-
make a digital signature of the generated inventory file,
-
send file(s) to the node’s policy server on
https://POLICY-SERVER/inventory-updates/
The individual commands can be displayed with the -i option to rudder agent
inventory command.
Processing inventories on relays
On the Relay server:
-
the inventory and its signature are received by a
webdavendpoint, -
the
webdavservice store the files in the folder/var/rudder/inventories/incoming -
on each agent runs, files in
/var/rudder/inventories/incomingare forwarded to the Relay own policy server.
Processing inventories on root server
On the Root server, the start of the workflow is the same than on a relay:
-
the inventory is received by a
webdavendpoint, -
the
webdavservice store the file in the folder/var/rudder/inventories/incoming(for nodes not already accepted in Rudder) or in/var/rudder/inventories/accepted-nodes-updates(for node already accepted).
As soon as a file is created or modified in these two directories, an inotify
event is sent to in inventory watcher process which:
-
check if the file is of any interest for it based on extension (
.ocs,.xml,.gz,.signextension are processed) -
if the file is an archive, it’s extracted,
-
if the file is a signature (respectively an inventory), it waits for the corresponding inventory (respectively signature) for up to 10s,
-
if only the signature is present, nothing is done (only a log),
-
if only the inventory file is present, the processing is done in "compatibility" mode to support rudder agent below version 5.0,
-
if the pair is present, both are processed together.
-
processing starts by parsing inventory file and check for mandatory elements (especially
<RUDDER>tag and content) -
then, inventory is queued to be saved in LDAP.
Queue of inventories waiting to be parsed
The inventory endpoint has a limited number of slot available for successfully
uploaded inventories to be queued waiting for parsing.
That number can be configured in file /opt/rudder/etc/inventory-web.properties:
waiting.inventory.queue.size=50
The number of currently waiting
inventories can be obtained via a local REST API call to
http://localhost:8080/endpoint/api/info:
$ curl http://localhost:8080/endpoint/api/info
{
"queueMaxSize": 50,
"queueFillCount": 50,
"queueSaturated": true
}
Start, stop, restart inventory watchers
Inventory inotify watcher can be controlled via local REST API call:
$ curl -X POST http://localhost:8080/endpoint/api/watcher/start
$ curl -X POST http://localhost:8080/endpoint/api/watcher/restart
$ curl -X POST http://localhost:8080/endpoint/api/watcher/stop
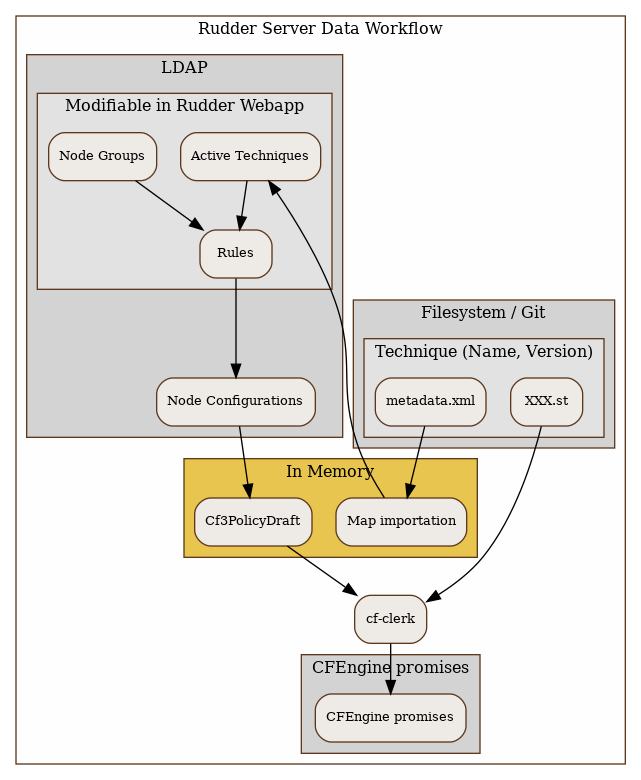
Rudder Server data workflow
To have a better understanding of the Archive feature of Rudder, a description of the data workflow can be useful.
All the logic of Rudder Techniques is stored on the filesystem in /var/rudder/configuration-repository/techniques. The files are under version control, using git. The tree is organized as following:
-
At the first level, techniques are classified in categories: applications, fileConfiguration, fileDistribution, jobScheduling, system, systemSettings. The description of the category is included in category.xml.
-
At the second and third level, Technique identifier and version.
-
At the last level, each technique is described with a metadata.xml file and one or several agent template files (name ending with .st).
+-- techniques
| +-- applications
| | +-- apacheServer
| | | +-- 1.0
| | | +-- apacheServerConfiguration.st
| | | +-- apacheServerInstall.st
| | | +-- metadata.xml
| | +-- aptPackageInstallation
| | | +-- 1.0
| | | +-- aptPackageInstallation.st
| | | +-- metadata.xml
| | +-- aptPackageManagerSettings
| | | +-- 1.0
| | | +-- aptPackageManagerSettings.st
| | | +-- metadata.xml
| | +-- category.xml
| | +-- openvpnClient
| | | +-- 1.0
| | | +-- metadata.xml
| | | +-- openvpnClientConfiguration.st
| | | +-- openvpnInstall.stAt Rudder Server startup, or after the user has requested a reload of the Rudder Techniques, each metadata.xml is mapped in memory, and used to create the LDAP subtree of Active Techniques. The LDAP tree contains also a set of subtrees for Node Groups, Rules and Node Configurations.
At each change of the Node Configurations, Rudder Server generates the agent policies for the Nodes.
Configuration files for Rudder Server
-
/opt/rudder/etc/htpasswd-webdav -
/opt/rudder/etc/inventory-web.properties -
/opt/rudder/etc/logback.xml -
/opt/rudder/etc/openldap/slapd.conf -
/opt/rudder/etc/reportsInfo.xml -
/opt/rudder/etc/rudder-users.xml -
/opt/rudder/etc/rudder-web.properties
Rudder agent workflow
|
Components
This agent contains the following tools:
These components are recognized for their reliability and minimal impact on performances. Our tests showed their memory consumption is usually under 10 MB of RAM during their execution. So you can safely install them on your servers. We grouped all these tools in one package, to ease the Rudder Agent installation. |
In this chapter, we will have a more detailed view of the Rudder Agent workflow. What files and processes are created or modified at the installation of the Rudder Agent? What is happening when a new Node is created? What are the recurrent tasks performed by the Rudder Agent? How does the Rudder Server handle the requests coming from the Rudder Agent? The Rudder Agent workflow diagram summarizes the process that will be described in the next pages.
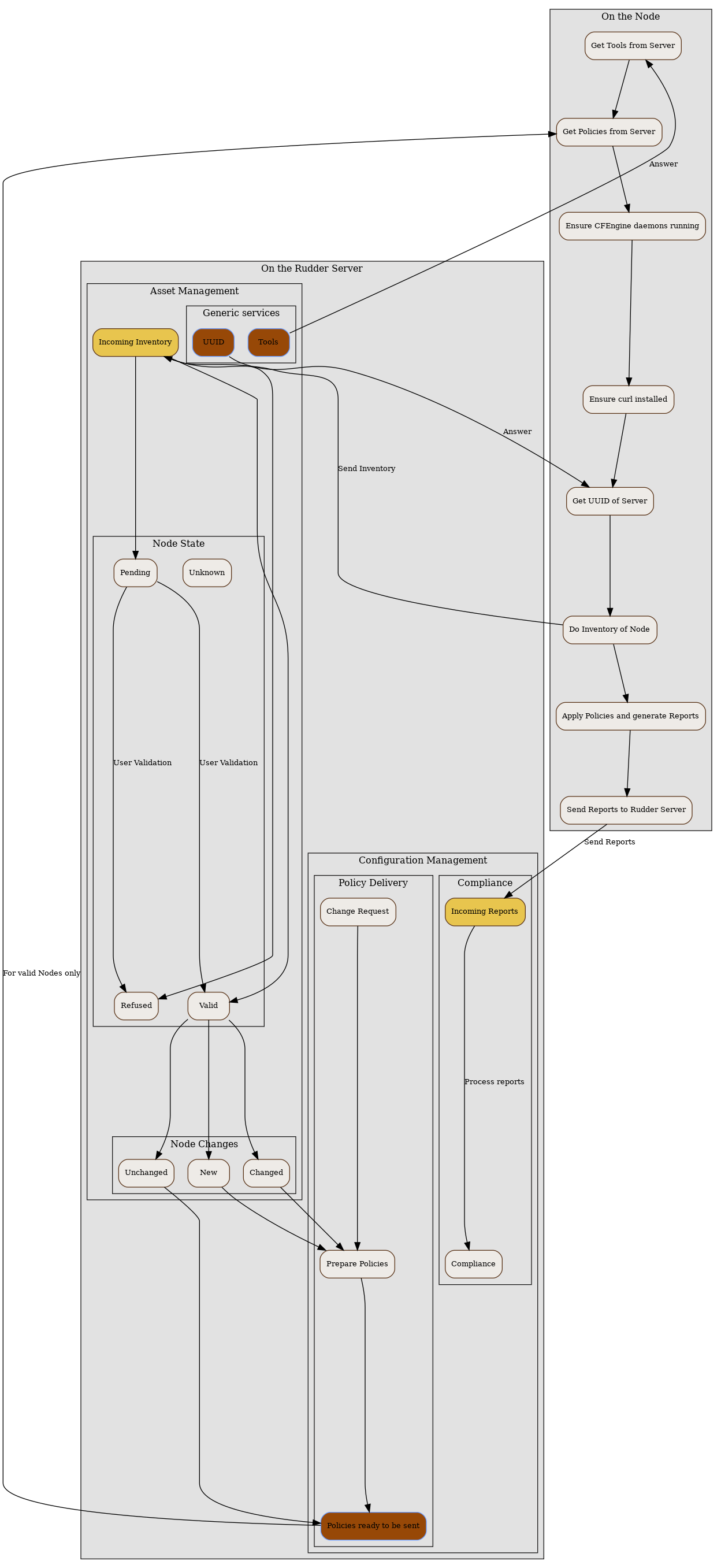
Let’s consider the Rudder Agent is installed and configured on the new Node.
The Rudder Agent is regularly launched and performs following tasks sequentially, in this order:
Request data from Rudder Server
The agent tries to fetch new Applied Policies from Rudder Server. Only requests from valid Nodes will be accepted. At first run and until the Node has been validated in Rudder, this step fails.
Launch processes
Ensure that the agent daemons cf-execd and cf-serverd are running. Try to start these daemons if they are not already started.
Add a line in /etc/crontab to launch cf-execd if it’s not running.
Ensure again that the agent daemons cf-execd and cf-serverd are running. Try to start these daemons if they are not already started.
Identify Rudder Root Server
Ensure the curl package is installed. Install the package if it’s not present.
Get the identifier of the Rudder Root Server, necessary to generate reports. The URL of the identifier is http://Rudder_root_server/uuid
Inventory
If no inventory has been sent since 8 hours, or if a forced inventory has been requested (class force_inventory is defined), do and send an inventory to the server.
rudder agent inventory
No reports are generated until the Node has been validated in Rudder Server.
Packages organization
Packages
Rudder components are distributed as a set of packages.
- rudder-webapp
-
Main package for the Rudder server. It includes :
-
the graphical interface for Rudder
-
the inventory reception service
-
the application server (namely jetty), it depends on a compatible Java 8 Runtime Environment
-
the Techniques (installed into /opt/rudder/share/techniques)
-
the database containing the inventory and configuration information (namely OpenLDAP)
-
- rudder-reports
-
Package for the database containing the logs sent by each Node and the reports computed by Rudder. This is a 'PostgreSQL' database using the 'PostgreSQL' engine of the distribution. The package has a dependency on the postgresl package, creates the database named rudder and installs the inialisation scripts for that database in /opt/rudder/etc/postgresql/*.sql.
- rudder-api-client
-
Package that contains a command line to access the Rudder server API and a library to access it from python.
- rudder-server-relay
-
Package to setup a Rudder relay. It must be installed on a system that should be used as relays.
- rudder-agent
-
One single package integrates everything needed for the Rudder Agent. It contains CFEngine Community, FusionInventory.
The rudder-agent package mays either depends on or embed a few libraries and utilities depending on their existence withing the target distribution.
- rudder-server-root
-
Package to ease installation of all Rudder services. This package depends on above packages.
← Zabbix Build packages from source →